ウェブ記事の引用について
ウェブ記事の引用について備忘録です。
日本語だと、JSTが、
という資料を出しています。 15ページを参照すると、
著者名. “ウェブページの題名”. ウェブサイトの名称. 更新日付. 入手先, (入手日付).
と出ています。
英語でも色々とルールの記載がありますが、 以下は、AMA (American Medical Association)の例です。
In English articles, the followings are examples of AMA.
References to news publications, including newspapers (print and online) and blogs, should include the following, in the order indicated: (1) name of author (if given), (2) title of article, (3) name of newspaper, (4) date of newspaper or date of publication online, (5) section (if applicable), (6) page number (if applicable), (7) online accessed date (if applicable), and (8) website address (if applicable). Note: Newspaper names are not abbreviated. If a city name is not part of the newspaper name, it may be added to the official name for clarity, as with Minneapolis in example 1.
References to reports published by departments or agencies of a government should include the following information, in the order indicated: (1) name of author (if given); (2) title of bulletin; (3) name of issuing bureau, agency, department, or other governmental division (note that in this position, Department should be abbreviated Dept; also note that if the US Government Printing Office is supplied as the publisher, it would be preferable to obtain the name of the issuing bureau, agency, or department); (4) date of publication; (5) page numbers (if specified); (6) publication number (if any); (7) series number (if given); (8) online accessed date (if applicable); and (9) web address (if applicable).
発表論文を参考文献とできると良いですが、時事問題などを扱う場合は、参照先がウェブ記事しかない場合もあります。
執筆者、記事(資料)タイトル、発行日、アクセス日、URLなどを記載して、どの記事かわかるようにしておきましょう。
症例報告の同意書の雛形
以前まとめた、
症例報告の同意について - Yoshi Nishikawa Blog
の記事に関連して、症例報告の同意書のテンプレートについてお問い合わせをいただくことが増えました。
備忘のために、症例報告の同意書の雛形について、各種団体が挙げているものをまとめておきます(2022/6/23時点のリンクです)。
公益財団法人 日本精神神経学会
https://www.jspn.or.jp/uploads/uploads/files/activity/rinri_example.pdf
日本統合失調症学会
一般社団法人 日本糖尿病学会 会誌「糖尿病」
http://www.fa.kyorin.co.jp/jds/uploads/journal-jp_consent_form.pdf
https://ciru.dept.showa.gunma-u.ac.jp/doctor-leadership/data/pdf/sanko_02.pdf
https://www.rinri.med.tohoku.ac.jp/portal/files/syoureihoukoku_20200401.pdf
https://osakaminami.hosp.go.jp/Rinri/setumeidoui.pdf
以上のような文面を参考にしつつ、自施設、診療科、投稿する学会や雑誌などの状況にあったものを作成の上、説明し、ご同意いただくのがよいでしょう。
個票と小票
今日は、備忘録として、個票と小票について記しておきます。
個票
「こひょう」の意味や使い方 わかりやすく解説 Weblio辞書
投票・集計・やアンケート等に使用された個々の票のこと。
アンケート調査など、一般的に用いられるのはこちらですね。
音が同じでしばしば間違われるのですが、これとは別に、「小票」という表記もあります。
小票
小票という言葉はどこで使われるのか?
人口動態調査の際に出てくる、出生小票と死亡小票。私の知る限り、この2つです。
人口動態調査票とは?
人口動態調査票は、出生票、死亡票、死産票、婚姻票、離婚票の5種であり、その概要は次のとおりである。
(1)出生票:出生の年月日、場所、体重、父母の氏名及び年齢等出生届に基づく事項
(2)死亡票:死亡者の生年月日、住所、死亡の年月日等死亡届に基づく事項
(3)死産票:死産の年月日、場所、父母の年齢等死産届に基づく事項
(4)婚姻票:夫妻の生年月、夫の住所、初婚・再婚の別等婚姻届に基づく事項
(5)離婚票:夫妻の生年月、住所、離婚の種類等離婚届に基づく事項
出典:人口動態調査 調査の概要|厚生労働省
小票という言葉はどこで出てくる?
では小票という言葉はどこででてくるのでしょうか。
上述の厚生労働省のHPによると、
ウ保健所長は、市区町村長から送付を受けた出生票に基づいて出生小票(出生票の写し)を、死亡票に基づいて死亡小票(死亡票の写し)を作成する。
と記載があります。出ましたね。小票。
ちなみに、以下はその作成について記したものです。 ・出生小票及び死亡小票等の作成について(◆平成07年04月17日統発第115号)
出生小票(出生票の写し)
死亡小票(死亡票の写し)
これらは、人口動態調査票自体ではなく、出生票と死亡票の写しだったことがわかりました。
まとめ
今回は個票と小票の言葉遣いについて振り返りました。
注意が必要なのは、出生小票・死亡小票、の2つです。これらは、法律に基づいて作成される、出生票や死亡票の写しのことでした。
そのほか、一般的なアンケート調査などの個々の票は個票でOKです。
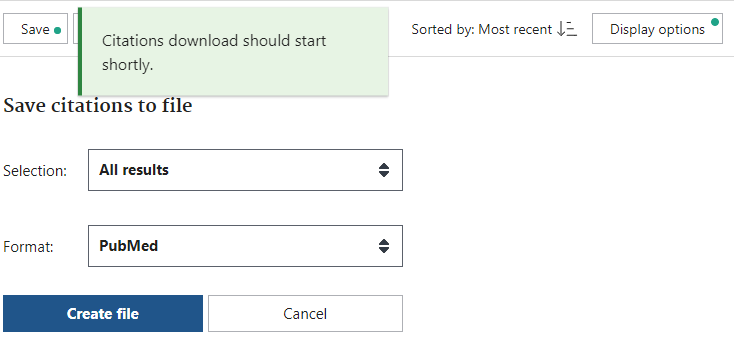
Pubmedの検索結果をRayyanに取り込む
システマティックレビューのときに、Rayyan – Intelligent Systematic Review を用いて文献管理をしている。
どうやって 検索結果を保存して、Rayyan に取り込むか。PubMed を用いた際の備忘録。

RにJAGSを認識させた(rjagsがloadできないときの対処)
JAGS
解析でJAGSを使うことになった(OSはWindows 10)。
JAGS: Just Another Gibbs Sampler
2021年10月11日時点の最新版はJAGS-4.3.0だ。
早速インストールする。
完了。
rjags
R上で使うためにrjagsを使う。
インストールして、呼び出す
install.packages("rjags")
library(rjags)
rjags が loadできない
要求されたパッケージ coda をロード中です
エラー: package or namespace load failed for ‘rjags’:
.onLoad は loadNamespace()('rjags' に対する)の中で失敗しました、詳細は:
call: fun(libname, pkgname)
error: Failed to locate any version of JAGS version 4
The rjags package is just an interface to the JAGS library
Make sure you have installed JAGS-4.x.y.exe (for any x >=0, y>=0) from
http://www.sourceforge.net/projects/mcmc-jags/files
loadできない。
ここでuser manualやinstallation manualを読むが解決せず。
おかしい。JAGS自体は入っている。
Rをアップデート
とりあえずR自体を最新版にアップデートしてみた。
エラー継続。。
RにJAGSを認識させた
認識していないR側の問題ではないか?と思い、
JAGSを認識させる方法を試してみることにした。
Sys.setenv(JAGS_HOME="C:\\Program Files\\JAGS\\JAGS-4.3.0")
JAGSの入っているディレクトリ(とJAGSのバージョン)を指定して、Rに認識させると・・・
library(rjags)
Linked to JAGS 4.3.0
Loaded modules: basemod,bugs
無事に読み込めた・・・!
ここで躓く方が少しでも減りますように。
Author contribution / 論文著者の役割
投稿規定に導入されている雑誌も多いですが、
ICMJE( International Committee of Medical Journal Editors)の下記ページが参考になります。
http://www.icmje.org/recommendations/browse/roles-and-responsibilities/defining-the-role-of-authors-and-contributors.html
これをみると、
1. Substantial contributions to the conception or design of the work; or the acquisition, analysis, or interpretation of data for the work; AND 2. Drafting the work or revising it critically for important intellectual content; AND 3. Final approval of the version to be published; AND 4. Agreement to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
とありますので、
1で構想・デザイン・データの取得・分析・解釈のうち1つ以上、
2で筆頭などはdraft、それ以外の著者はrevising
3, 4 は全員
最低限満たすかどうかが、著者の判断基準になるでしょう。
マルチレベルモデルの学習に良いウェブコンテンツ
Course topics | Centre for Multilevel Modelling | University of Bristol
地域研究などで多用される、「マルチレベルモデル」の学習には、このブリストル大学のウェブサイトが秀逸です。
登録すれば、無料で閲覧できます。